Êtes-vous un créateur de contenu ou un auteur de blog qui génère un contenu unique et de haute qualité pour gagner sa vie ? Avez-vous remarqué que les plateformes d’IA générative comme OpenAI ou CCBot utilisent votre contenu pour entraîner leurs algorithmes sans votre consentement ? Ne vous inquiétez pas! Vous pouvez empêcher ces robots d’accéder à votre site Web ou votre blog en utilisant le fichier robots.txt.
SOMMAIRE
Qu’est-ce qu’un fichier robots.txt ?
Un robots.txt n’est rien d’autre qu’un fichier texte qui indique aux robots, tels que les robots des moteurs de recherche, comment explorer et indexer les pages de leur site Web. Vous pouvez bloquer/autoriser les bons ou les mauvais robots qui suivent votre fichier robots.txt. La syntaxe est la suivante pour bloquer un seul bot à l’aide d’un user-agent :
user-agent: {BOT-NAME-HERE}
disallow: /Voici comment autoriser des robots spécifiques à explorer votre site Web à l’aide d’un agent utilisateur :
User-agent: {BOT-NAME-HERE}
Allow: /Où placer votre fichier robots.txt ?
Téléchargez le fichier dans le dossier racine de votre site Web. Votre URL ressemblera donc à :
https://example.com/robots.txt
https://blog.example.com/robots.txtConsultez les ressources suivantes sur robots.txt pour plus d’informations :
- Introduction au robots.txt de Google .
- Qu’est-ce que robots.txt ? | Comment fonctionne un fichier robots.txt depuis Cloudflare .
Comment bloquer les robots des robots d’exploration IA à l’aide du fichier robots.txt
La syntaxe est la même :
user-agent: {AI-Ccrawlers-Bot-Name-Here}
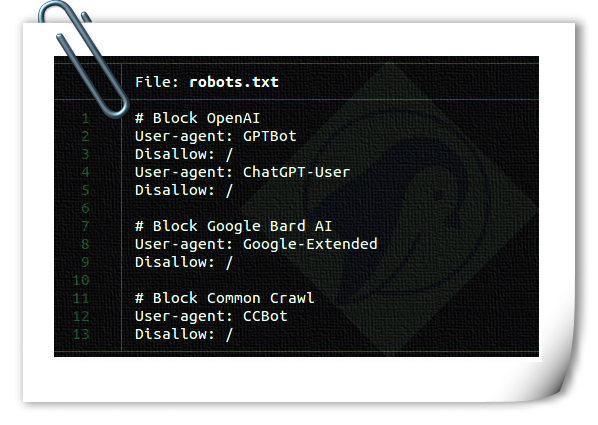
disallow: /Bloquer OpenAI à l’aide du fichier robots.txt
Ajoutez les quatre lignes suivantes à votre robots.txt :
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /Veuillez noter qu’OpenAI dispose de deux agents utilisateurs distincts pour l’exploration et la navigation sur le Web, chacun avec ses propres plages CIDR et IP. Pour configurer les règles de pare-feu répertoriées ci-dessous, vous aurez besoin d’une solide compréhension des concepts de mise en réseau et d’un accès au niveau racine à Linux. Si vous ne disposez pas de ces compétences, envisagez de faire appel aux services d’un administrateur système Linux pour empêcher l’accès à partir des plages d’adresses IP en constante évolution. Cela peut devenir un jeu du chat et de la souris.
#1 : L’ utilisateur ChatGPT est utilisé par les plugins dans ChatGPT
Voici une liste des agents utilisateurs utilisés par les robots d’exploration et les récupérateurs OpenAI, y compris les plages d’adresses CIDR ou IP pour bloquer son plugin AI bot que vous pouvez utiliser avec le pare-feu de votre serveur Web. Vous pouvez bloquer le 23.98.142.176/28 à l’aide de la commande ufw ou de la commande iptables sur votre serveur Web. Par exemple, voici une règle de pare-feu pour bloquer le CIDR ou la plage IP à l’aide d’UFW :
$ sudo ufw deny proto tcp from 23.98.142.176/28 to any port 80
$ sudo ufw deny proto tcp from 23.98.142.176/28 to any port 443#2 : Le GPTBot est utilisé par ChatGPT
Voici une liste des agents utilisateurs utilisés par les robots d’exploration et les récupérateurs OpenAI, y compris les plages d’adresses CIDR ou IP pour bloquer son robot IA que vous pouvez utiliser avec le pare-feu de votre serveur Web. Encore une fois, vous pouvez bloquer ces plages à l’aide de la commande ufw ou de la commande iptables . Voici un script shell pour bloquer ces plages CIDR :
#!/bin/bash
# Purpose: Block OpenAI ChatGPT bot CIDR
# Tested on: Debian and Ubuntu Linux
# ------------------------------------------------------------------
file="/tmp/out.txt.$$"
wget -q -O "$file" https://openai.com/gptbot-ranges.txt 2>/dev/null
while IFS= read -r cidr
do
sudo ufw deny proto tcp from $cidr to any port 80
sudo ufw deny proto tcp from $cidr to any port 443
done < "$file"
[ -f "$file" ] && rm -f "$file"Blocage de Google AI (API génératives Bard et Vertex AI)
Ajoutez les deux lignes suivantes à votre robots.txt :
User-agent: Google-Extended
Disallow: /Pour plus d’informations, voici une liste des agents utilisateurs utilisés par les robots d’exploration et les récupérateurs de Google. Cependant, Google ne fournit pas de CIDR, de plages d’adresses IP ou d’informations sur le système autonome (ASN) pour bloquer son robot IA que vous pouvez utiliser avec le pare-feu de votre serveur Web.
Blocage de Commoncrawl (CCBot) à l’aide du fichier robots.txt
Ajoutez les deux lignes suivantes à votre robots.txt :
User-agent: CCBot
Disallow: /Bien que Common Crawl soit une fondation à but non lucratif , tout le monde utilise des données pour entraîner son IA grâce à son bot appelé CCbot. Il est également essentiel de les bloquer. Cependant, tout comme Google, ils ne fournissent pas de CIDR, de plages d’adresses IP ou d’informations sur le système autonome (ASN) pour bloquer son robot IA que vous pouvez utiliser avec le pare-feu de votre serveur Web.
Bloquer Perplexity AI à l’aide du fichier robots.txt
Un autre service qui prend tout votre contenu et le réécrit à l’aide de l’IA générative. Vous pouvez le bloquer comme suit :
User-agent: PerplexityBot Disallow: /
Ils ont également publié des adresses IP que vous pouvez bloquer à l’aide de votre WAF ou du pare-feu de votre serveur Web.
Les robots IA peuvent-ils ignorer mon fichier robots.txt ?
Les entreprises bien établies telles que Google et OpenAI adhèrent généralement aux protocoles robots.txt. Mais certains robots IA mal conçus ignoreront votre robots.txt.
Est-il possible de bloquer les robots IA à l’aide de la technologie AWS ou Cloudflare WAF ?
Cloudflare a récemment annoncé avoir introduit une nouvelle règle de pare-feu capable de bloquer les robots IA. Cependant, les moteurs de recherche et autres robots peuvent toujours utiliser votre site Web/blog via ses règles WAF. Il est essentiel de se rappeler que les produits WAF nécessitent une compréhension approfondie du fonctionnement des robots et doivent être mis en œuvre avec soin. Sinon, cela pourrait également entraîner le blocage d’autres utilisateurs. Voici comment bloquer les robots IA à l’aide de Cloudflare WAF :
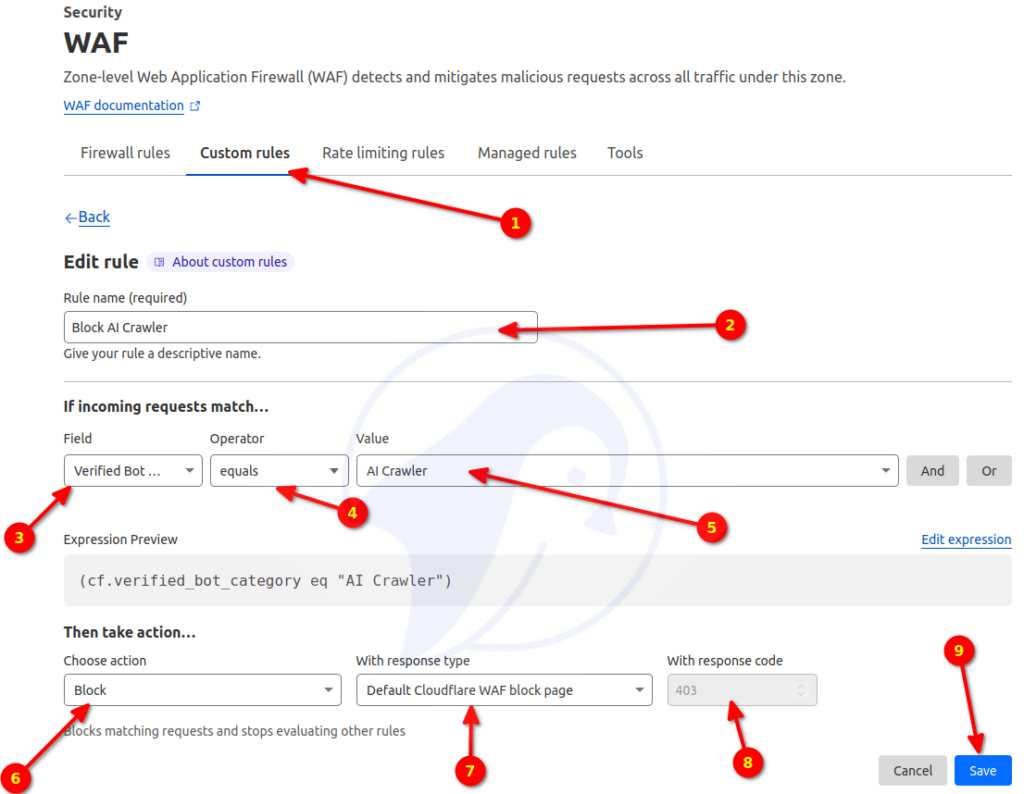
Veuillez noter que j’évalue la solution Cloudflare, mais mes tests principaux montrent qu’elle a bloqué au moins 3,31 % des utilisateurs. Les 3,31 % correspondent au taux CSR (Challenge Solve Rate), c’est-à-dire les humains ayant résolu le captcha fourni par Cloudflare. C’est un taux RSE élevé. Je dois faire plus de tests. Je mettrai à jour cet article de blog lorsque je commencerai à utiliser Cloudflare.
Puis-je bloquer l’accès à mon code et à mes documents hébergés sur GitHub et d’autres sites d’hébergement cloud ?
Non, je ne sais pas si c’est possible.
Je suis préoccupé par l’utilisation de GitHub, un produit Microsoft et le plus grand investisseur dans OpenAI. Ils peuvent utiliser vos données pour entraîner l’IA via leurs mises à jour ToS et d’autres failles. Il serait préférable que votre entreprise ou vous hébergeiez le serveur git de manière indépendante pour empêcher que vos données et votre code ne soient utilisés à des fins de formation. Les grandes entreprises comme Apple et d’autres interdisent l’utilisation interne de ChatGPT et de produits similaires car elles craignent que cela puisse entraîner une fuite de code et de données sensibles.
Est-il éthique de bloquer les robots IA pour les données de formation alors que l’IA est utilisée pour le bien de l’humanité ?
J’ai des doutes quant à l’utilisation d’OpenAI, de Google Bard, de Microsoft Bing ou de toute autre IA au profit de l’humanité. Cela ressemble à un simple programme lucratif, alors que l’IA générative remplace les emplois de cols blancs. Cependant, si vous avez des informations sur la manière dont mes données peuvent être utilisées pour guérir le cancer (ou des choses similaires), n’hésitez pas à les partager dans la section commentaires.
Ma pensée personnelle est que je ne bénéficie pas d’OpenAI/Google/Bing AI ou de toute autre IA pour le moment. J’ai travaillé très dur pendant plus de 20 ans et je dois protéger mon travail des profits directs de ces grandes technologies. Vous n’êtes pas obligé d’être d’accord avec moi. Vous pouvez donner votre code et d’autres éléments à l’IA. N’oubliez pas que c’est facultatif. La seule raison pour laquelle ils fournissent désormais le contrôle des robots.txt est que plusieurs auteurs de livres et entreprises les poursuivent devant les tribunaux. Outre ces problèmes, les outils d’IA sont utilisés pour créer des sites de spam et des livres électroniques.
Il est vrai que l’IA utilise déjà la majorité de vos données, mais quel que soit le contenu que vous créerez à l’avenir, il pourra être protégé grâce à ces techniques.
En conclusion
À mesure que l’IA générative devient plus populaire, les créateurs de contenu commencent à remettre en question l’utilisation des données par les sociétés d’IA pour entraîner leurs modèles sans autorisation. Ils profitent de votre code, de vos textes, images et vidéos créés par des millions de petits créateurs indépendants tout en leur supprimant leur source de revenus. Certains ne s’y opposeront peut-être pas, mais je sais qu’une décision aussi soudaine en dévaste beaucoup. Par conséquent, les opérateurs de sites Web et les créateurs de contenu devraient pouvoir bloquer facilement les robots d’exploration IA indésirables. Ce processus devrait être simple.
Je mettrai à jour cette page car davantage de robots seront disponibles pour bloquer via robots.txt et en utilisant des solutions cloud fournies par des tiers tels que Cloudflare et autres.
